Kotlinx Serialization - How the serialization process works
Now that we know the basic concepts of kotlin serialization and have also seen how to use it to serialize and deserialize data, let’s talk a bit about the library’s internal working and some of the important concepts.
Note: If you haven’t gone through the previous posts, you should take a look at those first.
The entire process of serialization is composed of two separate sub-processes:
- Serialization
- Encoding
Each of these processes has a single responsibility, which enables clear separation of roles and allows both to operate independently. This is the reason behind the extensibility and flexibility of the library. Please note that despite being independent, these operations are still sequential— encoding always takes place after serialization.
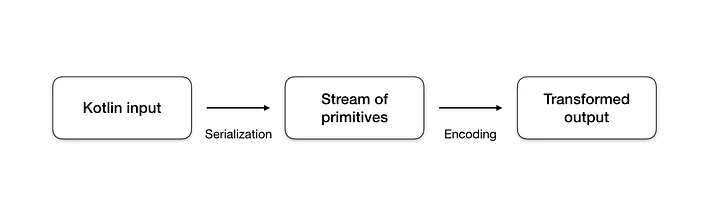
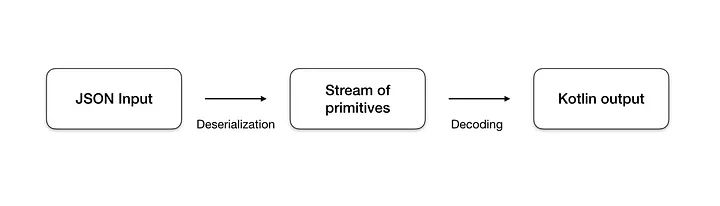
Serialization is the process of decomposing the input entity into a stream of primitive elements — characters, ints, booleans and so on — so that they can be ‘encoded’ by the encoder. This process can be recursive, meaning that any complex entities inside the input will be further broken into primitive elements. The process is considered completed once all of the input is converted to a stream of primitive elements, and there are no more complex entities remaining.
Encoding is the part where the input is actually processed. The stream of primitives generated by the serialization process are fed to the encoder as an input. The encoder’s action can be conversion to another desired format, storing, processing or transforming the data into some other format, or something else based on one’s requirements.
We’ll know more about Encoding in a later post, for now let’s focus our energies on the first part of the process — Serialization.
Remember the User object which we used to understand the basics in the introductory blog post? We’re going to use that to look into the workings of plugin and runtime.
@Serializable
data class User(val name: String)
Whenever we call User.serialize(), we obtain an object of type KSerializer. Let’s look into the generated code to know how things are structured and get a high level understanding of what’s going on inside, because Hey! code never lies :)
I’d highly suggest you to open up your IDE, paste the above code in a scratch file (if you don’t have it already) and decompile it to Java code by going to Tools > Kotlin > Show Kotlin Bytecode and then clicking on Decompile.
If you’ve ever inspected or played around with generated code for data classes before, you’d notice some similar code along with quite a lot of extra code. This code is generated by the @Serializable annotation, and mainly includes
- A synthetic, deprecated and inaccessible constructor
- A nested static class $serializer, also deprecated and inaccessible
The role of the constructor is to initialise the properties of the data class. Now, as this constructor is hidden, it must be used internally in the same class. If we look closely, the constructor is used during deserialization of data to create the class object, in our case a User object.
The $serializer class is what contains all the logic for the serialization process. This generated class implements an interface called GeneratedSerializer, which in-turn implements the KSerializer interface and overrides a number of methods. KSerializer governs the serialization and deserialization process for an object by defining strategies for serialization and deserialization — SerializationStrategy & DeserializationStrategy. These are responsible for defining how the actual serialization and deserialization of an object work. The interface also defines an object of type
SerialDescriptor, which contains metadata related to the object and describes internal structure of data to be transformed.
If we look back at the generated class $serializer, we see a SerialDescriptor object, along with two methods which use this object:
- serialize() — This method is defined in SerializationStrategy interface and its implementation describes the actual serialization process. It receives the value to be encoded and dispatches one or multiple commands to the Encoder to transform the value.
- deserialize() — This method is defined in DeserializationStrategy interface and its implementation describes the actual deserialization process. It receives the value to be decoded and dispatches one or multiple commands to the Decoder to transform the value. The major implementation difference is that unlike serialize(), this method needs to handle values coming in an arbitrary order so that values are bound to the desired properties.
Both the Encoder/Decoder expose only structural methods to the external world, while encapsulating the internal implementation of the format the data is being serialized to.
Hope this was helpful and you learnt something new. If you haven’t gone through the previous posts, you should take a look at those.
Hope it helps!
Originally posted on Medium link